Budowany model regresji logistycznej (podobnie jak liniowej regresji wielorakiej) pozwala na zbadanie wpływu wielu zmiennych niezależnych (X1,X2, . . . ,Xk) na jedną zmienną zależną (Y). Tym razem jednak zmienna zależna przyjmuje jedynie dwie wartości, np. chory/zdrowy, niewypłacalny/wypłacalny itp. Owe dwie wartości kodowane są jako (1)/(0) gdzie: (1) –wartość wyróżniona –posiadanie danej cechy, (0) –brak danej cechy.
Funkcja, na której oparty jest model regresji logistycznej wylicza nie dwupoziomową zmienną Y , a prawdopodobieństwo przyjęcia przez tą zmienną wyróżnionej wartości:
gdzie: P to prawdopodobieństwo przyjęcia wartości wyróżnionej (1) pod warunkiem uzyskania konkretnych wartości zmiennych niezależnych, tzw. prawdopodobieństwo przewidywane dla 1.
Zmienne fikcyjne i interakcje w modelu
Omówienie przygotowania zmiennych fikcyjnych i interakcji przedstawiono w rozdziale: Przygotowanie zmiennych do analizy w modelach wielowymiarowych. Uwaga!
Funkcja Z może być również opisana zależnością wyższego stopnia np. kwadratową - do modelu wprowadzamy wówczas zmienną zawierającą kwadrat danej zmiennej niezależnej Xi2.
Logitem nazywamy przekształcenie tego modelu do postaci:
Macierze biorące udział w równaniu, dla próby o liczności n, zapisujemy następująco:
Rozwiązaniem równania jest wówczas wektor ocen parametrów β1,β2, . . .βk nazywanych współczynnikami regresji:
Współczynniki te szacowane są poprzez metodę największej wiarygodności czyli poprzez poszukiwanie maksimum funkcji wiarygodności L (w programie użyto algorytm iteracyjny Newton-Raphson) . Na podstawie tych wartości możemy wnioskować o wielkości wpływu zmiennej niezależnej (dla której ten współczynnik został oszacowany) na zmienną zależną. Każdy współczynnik obarczony jest pewnym błędem szacunku.
Uwaga!
Budując model należy pamiętać, że liczba obserwacji powinna być dziesięciokrotnie większa lub równa liczbie szacowanych parametrów modelu (n 10(k + 1)).
Uwaga!
Budując model należy pamiętać, że zmienne niezależne nie powinny być współliniowe. W przypadku gdy występuje współliniowość, estymacja może być niepewna a uzyskane wartości błędów bardzo wysokie. Zmienne współliniowe należy usunąć z modelu bądź zbudować z nich jedną zmienna niezależną np. zamiast współliniowych zmiennych: wiek matki i wiek ojca można zbudować zmienną wiek rodziców.
Uwaga!
Kryterium zbieżności funkcji algorytmu iteracyjnego Newtona-Raphsona można kontrolować przy pomocy dwóch parametrów: limitu iteracji zbieżności (podaje maksymalną ilość iteracji w jakiej algorytm powinien osiągnąć zbieżność) i kryterium zbieżności (podaje wartość poniżej której uzyskana poprawa estymacji uznana będzie za nieznaczną i algorytm zakończy działanie).
Iloraz Szans
Jednostkowy Iloraz Szans
Na podstawie współczynników, dla każdej zmiennej niezależnej w modelu, wylicza się łatwą w interpretacji miarę jaką jest jednostkowy Iloraz Szans. Otrzymany Iloraz Szans wyraża zmianę szansy na wystąpienie wyróżnionej wartości (1), gdy zmienna niezależna rośnie o 1 jednostkę. Wynik ten jest skorygowany o pozostałe zmienne niezależne znajdujące się w modelu w ten sposób, że zakłada iż pozostają one na stałym poziomie podczas, gdy badana zmienna niezależna rośnie o jednostkę.
Wartość OR interpretujemy następująco:
OR > 1 oznacza stymulujący wpływ badanej zmiennej niezależnej na uzyskanie wyróżnionej wartości (1), tj. mówi o ile wzrasta szansa na wystąpienie wyróżnionej wartości (1), gdy zmienna niezależna wzrasta o jeden poziom.
OR < 1 oznacza destymulujący wpływ badanej zmiennej niezależnej na uzyskanie wyróżnionej wartości (1), tj. mówi o ile spada szansa na wystąpienie wyróżnionej wartości (1), gdy zmienna niezależna wzrasta o jeden poziom.
OR ≈ 1 oznacza, że badana zmienna niezależna nie ma wpływu na uzyskanie wyróżnionej
wartości (1).
Weryfikacja modelu
Istotność statystyczna poszczególnych zmiennych w modelu (istotność ilorazu szans)
Na podstawie współczynnika oraz jego błędu szacunku możemy wnioskować czy zmienna niezależna, dla której ten współczynnik został oszacowany wywiera istotny wpływ na zmienną zależną. W tym celu posługujemy się testem Walda.
lub równoważnie
Statystyka testowa ma asymptotycznie (dla dużych liczności) rozkład z chi-kwadrat z 1 stopniem swobody. Wyznaczoną na podstawie statystyki testowej wartość p porównujemy z poziomem
istotności α
jeżeli p ≤α ⇒ odrzucamy H0 przyjmując H1,
jeżeli p >α ⇒ nie ma podstaw odrzucić H0.
Jakość zbudowanego modelu regresji logistycznej możemy ocenić kilkoma miarami:
Kryteria informacyjne opierają się na entropii informacji niesionej przez model (niepewności modelu) tzn. szacują utraconą informację, gdy dany model jest używany do opisu badanego zjawiska. Powinniśmy zatem wybierać model o minimalnej wartości danego kryterium informacyjnego. AIC, AICc i BIC jest rodzajem kompromisu pomiędzy dobrocią dopasowania i złożonością. Drugi element sumy we wzorach na kryteria informacyjne (tzw. funkcja straty lub kary) mierzy prostotę modelu. Zależy on od liczby prarametrów w modelu (k) i liczności próby (n). W obu przypadkach element ten rośnie wraz ze wzrostem liczby parametrów i wzrost ten jest tym szybszy im mniejsza jest liczba obserwacji. Kryterium informacyjne nie jest jednak miarą absolutną, tzn. jeśli wszystkie porównywane modele źle opisują rzeczywistość w kryterium informacyjnym nie ma sensu szukać ostrzeżenia.
Pseudo R2 – tzw. McFadden R2 jest miarą dopasowania modelu (odpowiednikiem współczynnika determinacji wielorakiej R2 wyznaczanego dla liniowej regresji wielorakiej). Wartość tego współczynnika mieści się w przedziale < 0; 1), gdzie wartości bliskie 1 oznaczają doskonałe dopasowanie modelu, 0 – zupełny bark dopasowania. Wadą współczynnika Pseudo R2 jest wrażliwość na ilość zmiennych w modelu i brak możliwości osiągnięcia górnej granicy 1. Dlatego też wyznacza się jego poprawioną wartość: R2Nagelkerke i R2Cox-Snell
Istotność statystyczna wszystkich zmiennych w modelu
Podstawowym narzędziem szacującym istotność wszystkich zmiennych w modelu jest test ilorazu wiarygodności. Test ten weryfikuje hipotezę:
:
wszystkie βi = βi,
:
nie wszystkie βi ≠ βi.
Statystyka testowa ma asymptotycznie (dla dużych liczności) rozkład z chi-kwadrat z k stopniami swobody. Wyznaczoną na podstawie statystyki testowej wartość p porównujemy z poziomem istotności α
jeżeli p ≤α ⇒ odrzucamy H0 przyjmując H1,
jeżeli p >α ⇒ nie ma podstaw odrzucić H0.
Test Hosmera-Lemeshowa
Test ten, dla różnych podgrup danych, porównuje obserwowane liczności występowania wartości wyróżnionej Og i przewidywane prawdopodobieństwo Eg. Jeśli Og i Eg są wystarczająco bliskie, wówczas można założyć, że zbudowano dobrze dopasowany model.
Hipotezy:
:
Og = Eg dla wszystkich kategorii,
:
Og ≠ Eg dla przynajmniej jednej kategorii,
Wyznaczoną na podstawie statystyki testowej wartość p porównujemy z poziomem istotności α
jeżeli p ≤α ⇒ odrzucamy H0 przyjmując H1,
jeżeli p >α ⇒ nie ma podstaw odrzucić H0.
AUC - pole pod krzywą ROC - Krzywa ROC, zbudowana w oparciu o wartość zmiennej zależnej oraz przewidywane prawdopodobieństwo zmiennej zależnej P, pozwala na ocenę zdolności zbudowanego modelu regresji logistycznej do klasyfikacji przypadków do dwóch grup: (1) i (0). Powstała w ten sposób krzywa, a w szczególności pole pod nią, obrazuje jakość klasyfikacyjną modelu. Gdy krzywa ROC pokrywa się z przekątną y = x, to decyzja o przyporządkowaniu przypadku do wybranej klasy (1) lub (0) podejmowana na podstawie modelu jest tak samo dobra jak losowy podział badanych przypadków do tych grup. Jakość klasyfikacyjna modelu jest dobra, gdy krzywa znajduje się znacznie powyżej przekątnej y = x, czyli gdy pole pod krzywą ROC jest znacznie większe niż pole pod prostą y = x, zatem większe niż 0.5.
Hipotezy:
:
AUC = 0.5,
:
AUC ≠ 0.5.
Wyznaczoną na podstawie statystyki testowej wartość p porównujemy z poziomem istotności α
jeżeli p ≤α ⇒ odrzucamy H0 przyjmując H1,
jeżeli p >α ⇒ nie ma podstaw odrzucić H0.
Dodatkowo, dla krzywej ROC podawana jest proponowana wartość punktu odcięcia prawdopodobieństwa przewidywanego, oraz tabela podająca wielkość czułości i swoistości dla
każdego możliwego punktu odcięcia.
Uwaga!
Więcej możliwości w wyliczeniu punktu odcięcia daje moduł Krzywa ROC. Analizę przeprowadzamy na podstawie wartości obserwowanych i prawdopodobieństwa przewidywanego, które uzyskujemy w analizie regresji logistycznej.
Klasyfikacja
Na podstawie wybranego punktu odcięcia prawdopodobieństwa przewidywanego można sprawdzić jakość klasyfikacji. Punkt odcięcia, to domyślnie wartość 0.5. Użytkownik może zmienić tę wartość na dowolną wartość z przedziału (0, 1) np. wartość sugerowaną przez krzywą ROC.
W wyniku uzyskamy tabelę klasyfikacji oraz procent poprawnie zaklasyfikowanych przypadków, procent poprawnie zaklasyfikowanych (0) –swoistość oraz procent poprawnie zaklasyfikowanych (1) –czułość.
Predykcja na podstawie modelu
Na podstawie wybranego punktu odcięcia prawdopodobieństwa przewidywanego oraz zadanych wartości zmiennych niezależnych, można wyliczyć przewidywaną wartość zmiennej zależnej (0) lub (1). Punkt odcięcia, to domyślnie wartość 0.5. Użytkownik może zmienić tę wartość na dowolną wartość z przedziału (0, 1) np. wartość sugerowaną przez krzywą ROC.
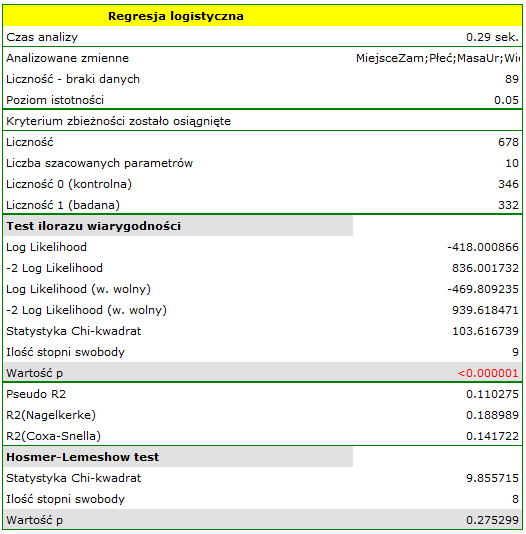
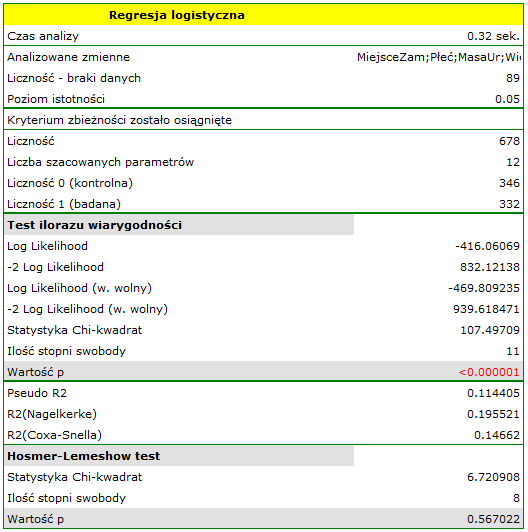
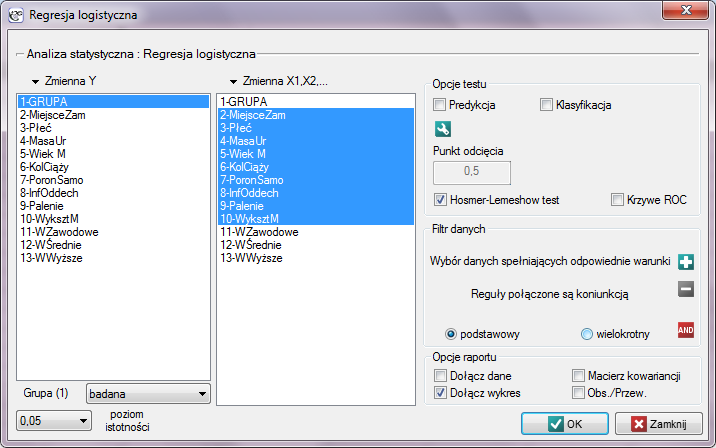
Przeprowadzono badanie mające na celu identyfikację czynników ryzyka pewnej rzadko występującej wady wrodzonej u dzieci. W badaniu wzięło udział 395 matek dzieci z ta wadą oraz 375 matek dzieci zdrowych. Zebrane dane to: miejsce zamieszkania, płeć dziecka, masa urodzeniowa dziecka, wiek matki, kolejność ciąży, przebyte poronienia samoistne, infekcje oddechowe, palenie tytoniu, wykształcenie matki.
Budujemy model regresji logistycznej by sprawdzić które zmienne mogą wywierać istotny wpływ na występowanie wady. Jako zmienną zależną ustawiamy kolumnę GRUPA, wartością wyróżnioną w tej zmiennej jako 1 jest grupa "badana", czyli matki dzieci z wadą wrodzoną. Kolejne 9 zmiennych, to zmienne niezależne:
MiejsceZam (2=miasto/1=wieś),
Płeć (1=mężczyzna/0=kobieta),
MasaUr (w kilogramach z dokładnością do 0.5kg),
WiekM (w latach),
KolCiąży (dziecko z której ciąży),
PoronSamo (1=tak/0=nie),
InfOddech (1=tak/0=nie),
Palenie (1=tak/0=nie),
WyksztM (1=podstawowe lub niżej/2=zawodowe/3=średnie/4=wyższe).
Jakość dopasowania modelu nie jest wysoka (R2Pseudo = 0.11, R2Nagelkerke = 0.19 i R2Cox-Snell = 0.14). Jednocześnie model jest istotny statystycznie (wartość p < 0.000001 testu ilorazu wiarygodności), a zatem część zmiennych niezależnych znajdujących się w modelu jest istotna statystycznie. Wynik testu Hosmera-Lemeshowa wskazuje na brak istotności (p = 0.2753). Przy czym, w przypadku testu Hosmera-Lemeshowa pamiętamy o tym, że brak istotności jest pożądany, bo wskazuje na podobieństwo liczności obserwowanych i prawdopodobieństwa przewidywanego.
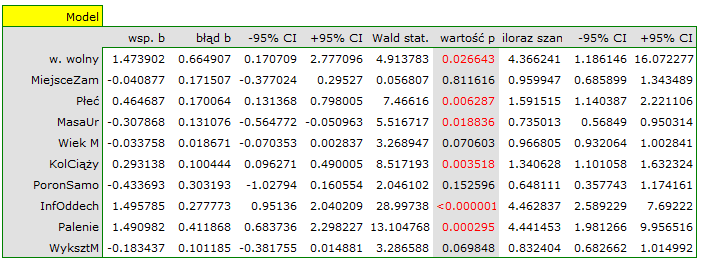
Interpretacja poszczególnych zmiennych w modelu zaczyna się od sprawdzenia ich istotności. W tym przypadku zmienne, które w istotny sposób są związane z występowaniem wady to:
Płeć: p = 0.0063,
MasaUr: p = 0.0188,
KolCiąży: p = 0.0035,
InfOddech: p < 0.000001,
Palenie: p = 0.0003.
Badana wada wrodzona jest wadą rzadką, ale szansa na jej wystąpienie zależy od wymienionych zmiennych w sposób opisany poprzez iloraz szans:
zmienna Płeć: OR[95%CI] = 1.60[1.14; 2.22] –szansa wystąpienia wady u chłopca jest 1.6 krotnie większa niż u dziewczynki;
zmienna MasaUr: OR[95%CI] = 0.74[0.57; 0.95] –im wyższa masa urodzeniowa, tym szansa wystąpienia wady u dziecka jest mniejsza;
zmienna KolCiąży: OR[95%CI] = 1.34[1.10; 1.63] –szansa wystąpienia wady u dziecka wzrasta wraz z każdą kolejną ciążą 1.34 krotnie;
zmienna InfOddech: OR[95%CI] = 4.46[2.59; 7.69] –szansa wystąpienia wady u dziecka, gdy matka w czasie ciąży przechodziła infekcje oddechową jest 4.46 krotnie większa niż gdyby jej nie przechodziła;
zmienna Palenie: OR[95%CI] = 4.44[1.98; 9.96] –matka paląca w czasie ciąży zwiększa 4.44 krotnie szansę na wystąpienia wady u dziecka.
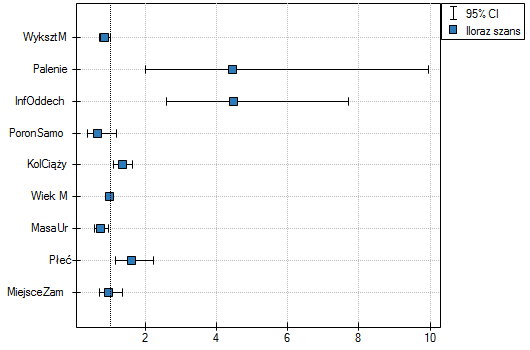
W przypadku zmiennych nieistotnych statystycznie przedział ufności dla Ilorazu Szans zawiera jedynkę co oznacza, że zmienne te nie zwiększają ani nie zmniejszają szansy na wystąpienie badanej wady. Nie można więc interpretować uzyskanego ilorazu w podobny sposób jak dla zmiennych istotnych statystycznie.
Wpływ poszczególnych zmiennych niezależnych na występowanie wady możemy równiez opisać przy pomocy wykresu dotyczącego iloraz szans:
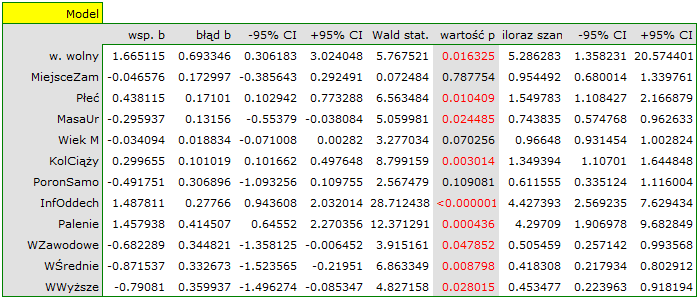
Zbudujemy raz jeszcze model regresji logistycznej, ale tym razem zmienną wykształcenie rozbijemy na zmienne fikcyjne (kodowanie zero-jedynkowe). Tracimy tym samym informację o uporządkowaniu kategorii wykształcenia, ale zyskujemy możliwość wnikliwszej analizy poszczególnych kategorii. Rozbicia na zmienne fikcyjne dokonano tworząc 3 zmienne dotyczące wykształcenia:
Brak jest zmiennej dotyczącej wykształcenia podstawowego, ponieważ będzie ono stanowić kategorię odniesienia.
W rezultacie zmienne opisujące wykształcenie stają się istotne statystycznie. Dopasowanie modelu nie ulega znacznej zmianie, ale zmienia się sposób interpretacji ilorazu szans dla wykształcenia:
Zmienna
OR[95%CI]
Wykształcenie podstawowe
kategoria referencyjna
Wykształcenie zawodowe
0.51[0.26; 0.99]
Wykształcenie średnie
0.42[0.22; 0.80]
Wykształcenie wyższe
0.45[0.22; 0.92]
Szansa na wystąpienie badanej wady w każdej kategorii wykształcenia odnoszona jest zawsze do szansy wystąpienia wady przy wykształceniu podstawowym. Widzimy, że dla bardziej wykształconych matek, iloraz szans jest niższy. Dla matki z wykształceniem:
zawodowym szansa wystąpienia wady u dziecka stanowi 0.51 część szansy na urodzenie dziecka z wadą jaką ma matka z wykształceniem podstawowym;
średnim szansa wystąpienia wady u dziecka stanowi 0.42 część szansy na urodzenie dziecka z wadą jaką ma matka z wykształceniem podstawowym;
wyższym szansa wystąpienia wady u dziecka stanowi 0.45 część szansy na urodzenie dziecka z wadą jaką ma matka z wykształceniem podstawowym.
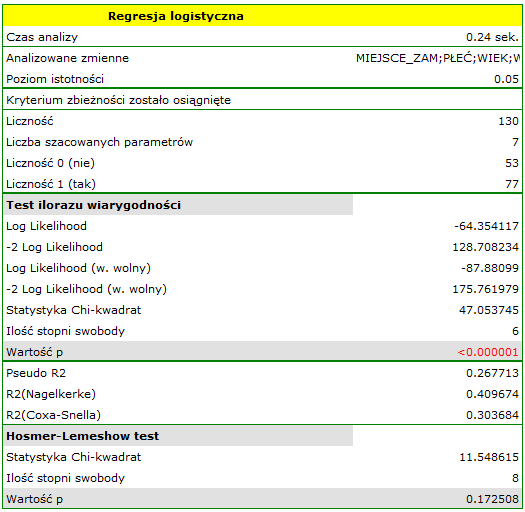
Przeprowadzono eksperyment mający na celu zbadanie umiejętność koncentracji grupy dorosłych podczas sytuacji niekomfortowych. W eksperymencie wzięło udział 130 osób. Każda badana osoba dostała pewne zadanie, którego rozwiązanie wymagało skupienia uwagi. Podczas eksperymentu niektóre osoby zostały poddane działaniu czynnika zakłócającego jakim była podwyższona temperatura powietrza do 32 stopni Celsiusza. Osoby biorące udział w eksperymencie zapytano dodatkowo o ich miejsce zamieszkania, płeć, wiek i wykształcenie. Czas na rozwiązanie zadania ograniczono do 45 minut. Dla osób, które skończyły przed czasem odnotowano rzeczywisty czas poświęcony na rozwiązanie.
Zmienna ROZWIĄZANIE (tak/nie) zawiera wynik eksperymentu, czyli informację o tym, czy zadanie zostało rozwiązane poprawnie czy też nie. Pozostałe zmienne, które mogły wpływać na wynik eksperymentu to:
MIEJSCEZAM (1=miasto/0=wieś),
PŁEĆ (1=kobieta/0=mężczyzna),
WIEK (w latach),
WYKSZTAŁCENIE (1=podstawowe, 2=zawodowe, 3=średnie, 4=wyższe),
CZAS rozwiązywania (w minutach),
ZAKŁÓCENIA (1=tak/0=nie).
Na bazie wszystkich zmiennych zbudowano model regresji logistycznej, gdzie jako stan wyróżniony zmiennej ROZWIĄZANIE wybrano "tak".
Jakość jego dopasowania opisują współczynniki: R2Pseudo = 0.27, R2Nagelkerke = 0.41 i R2Cox-Snell = 0.30. Na wystarczającą jakość dopasowania wskazuje również wynik testu Hosmera-Lemeshowa (p = 0.1725). Cały model jest istotny statystycznie o czym mówi wynik testu ilorazu wiarygodności (p <0.000001).
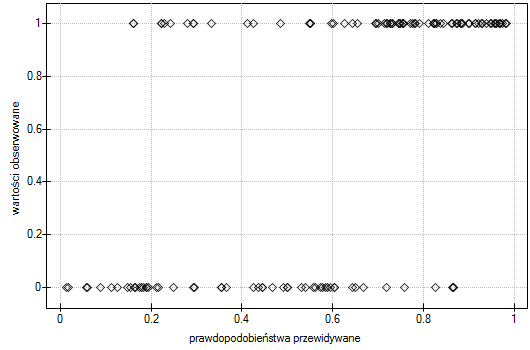
Wartości obserwowane i prawdopodobieństwo przewidywane możemy zobaczyć na wykresie:
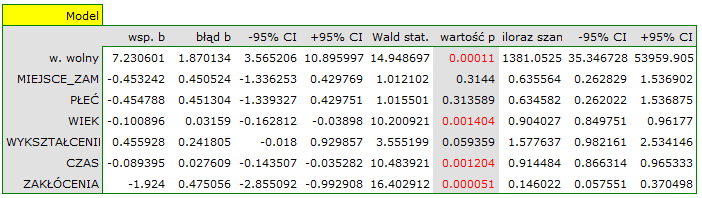
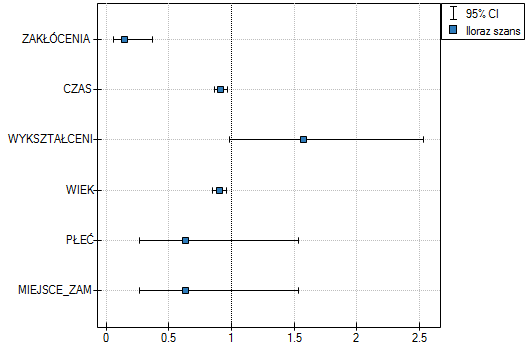
W modelu zmienne, które w sposób istotny wpływają na wynik to:
WIEK: p = 0.0014,
CZAS: p = 0.0012,
ZAKŁÓCENIA: p = 0.0001.
Przy czym, im osoba rozwiązująca jest młodsza, czas rozwiązywania krótszy i brak jest czynnika zakłócającego,
tym większe prawdopodobieństwo poprawnego rozwiązania:
Uzyskane wyniki Ilorazu Szans przedstawiono na poniższym wykresie:
Jeśli model miałby zostać użyty do prognozowania, to należy przyjrzeć się jakości klasyfikacji. Wyliczamy w tym celu krzywe ROC.
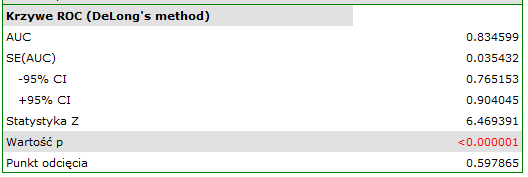
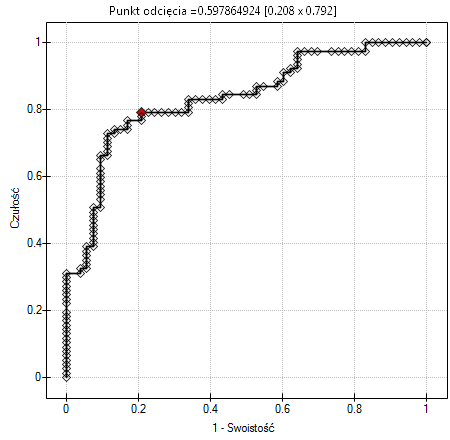
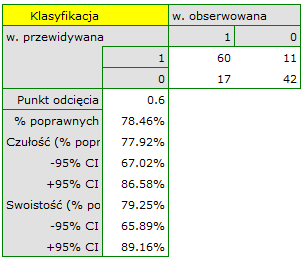
Rezultat wydaje się zadowalający. Pole pod krzywą wynosi AUC = 0.83 i jest istotnie większe niż 0.5 (p < 0.000001), więc na podstawie zbudowanego modelu można klasyfikować. Proponowany punkt odcięcia dla krzywej ROC wynosi 0.60 i jest nieco wyższy niż standardowo używany w regresji poziom 0.5. Klasyfikacja wyznaczona na bazie tego punktu odcięcia daje 78.46% przypadków zaklasyfikowanych poprawnie, z czego poprawnie zaklasyfikowanych wartości "tak" jest 77.92% (czułość[95%CI] = 77.92%[67.02%; 86.58%]), wartości "nie" jest 79.25% (swoistość[95%CI] = 79.25%[65.89%; 89.16%]).
Na tym etapie możemy zakończyć analizę klasyfikacji, lub jeśli wynik nie jest wystarczający bardziej wnikliwą analizę krzywej ROC możemy przeprowadzić w module Krzywa ROC.
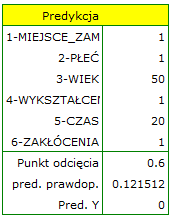
Ponieważ uznaliśmy, że klasyfikacja na podstawie modelu jest zadowalająca, możemy wyliczyć prognozowaną wartość zmiennej zależnej dla dowolnie zadanych warunków. Sprawdźmy jakie szanse na rozwiązanie zadania ma osoba dla której:
MIEJSCEZAM (1=miasto),
PŁEĆ (1=kobieta),
WIEK (50 lat),
WYKSZTAŁCENIE (1=podstawowe),
CZAS rozwiązywania (20 minut),
ZAKŁÓCENIA (1=tak).
W tym celu na podstawie wartości współczynnika b wyliczane jest prawdopodobieństwo przewidywane (prawdopodobieństwo uzyskania odpowiedzi "tak" pod warunkiem określenia wartości zmiennych zależnych). W rezultacie tych obliczeń program zwróci wynik:
Uzyskane prawdopodobieństwo rozwiązania zadania wynosi 0.1215, więc na podstawie punktu odcięcia 0.60 przewidziany wynik to 0 –czyli zadanie nie rozwiązane poprawnie.
 Modele wielowymiarowe
Modele wielowymiarowe
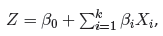
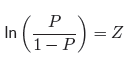

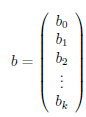
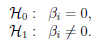
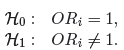
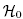 :
wszystkie βi = βi,
:
wszystkie βi = βi,
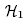 :
nie wszystkie βi ≠ βi.
:
nie wszystkie βi ≠ βi.