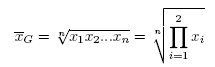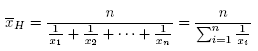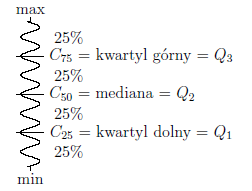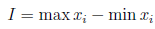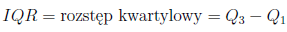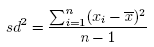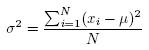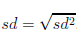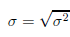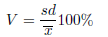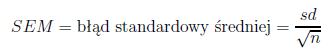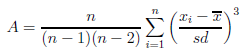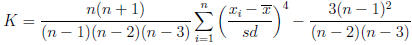Celem stosowania metod statystyki opisowej jest podsumowanie zbioru danych poprzez
pewne charakterystyki np. poprzez wartość średniej, mediany czy odchylenia standardowego, oraz wyciągnięcie pewnych podstawowych wniosków i uogólnień na temat zbioru.
W oknie Statystk opisowych wybieramy zmienną do analizy oraz opcje analizy i zaznaczamy interesujące
nas miary statystyk opisowych. Przy czym zaznaczać można pojedyncze statystyki lub
grupy statystyk wybierając przycisk . Dokonany wybór potwierdzamy przyciskiem OK.
Wynik dokonanej analizy znajdzie się w raporcie dołączonym do arkusza danych, dla
których analiza została wykonana.
Dodatkowo, jeśli chcemy by dane zostały zobrazowane za pomocą wykresu ramka-wąsy, wówczas w oknie Statystyk opisowych zaznaczamy opcję Dołącz wykres.
Miary tendencji centralnej są to tzw. miary przeciętne charakteryzujące średni lub typowy
poziom wartości cechy.
Średnia arytmetyczna
gdzie xi to kolejne wartości zmiennej a n - liczebność próby.
Średnia arytmetyczna jest stosowana dla skali interwałowej. Dla próby przyjmuje się ją oznaczać przez a dla populacji przez µ.
Średnia geometryczna
Średnia ta jest stosowana dla skali interwałowej, gdy zmienna ma rozkład logarytmiczno-normalny (logarytm zmiennej ma rozkład normalny).
Średnia harmoniczna
Średnia ta jest stosowana dla skali interwałowej.
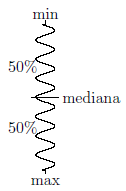
Mediana
W uporządkowanym zbiorze danych mediana jest wartością dzielącą ten zbiór na dwie równe części.
Połowa wszystkich obserwacji znajduje się poniżej, a połowa powyżej mediany.
Mediana może być stosowana w skali interwałowej oraz porządkowej.
Moda
Moda – jest to wartość obserwacji, która występuje najczęściej wśród uzyskanych pomiarów. Moda może być stosowana w każdej skali i jest wyrażona w tych samych jednostkach co wyniki pomiarów.
INNE MIARY POŁOŻENIA:
Kwartyle, decyle, centyle
Kwartyle (Q1,Q2,Q3) dzielą uporządkowany szereg na 4 równe
części, decyle (Di, i = 1, 2, ..., 9) na 10 równych części a centyle (percentyle: Ci, i = 1, 2, ..., 99)
na sto równych części. Drugi kwartyl, piąty decyl i pięćdziesiąty centyl są równe medianie. Miery te mogą być stosowane w skali interwałowej oraz
porządkowej.
Znajomość miar tendencji centralnej nie wystarcza do scharakteryzowania struktury zbiorowości statystycznej. Badana grupa może charakteryzować się różnym stopniem zmienności w zakresie badanej cechy. Potrzebne są zatem formuły pozwalające wyznaczyć wartości, które charakteryzują rozrzut danych.
Miary rozproszenia są liczone tylko dla skali interwałowej, ponieważ bazują one na odległościach między punktami.
Rozstęp
gdzie xi to wartości badanej zmiennej
gdzie Q1,Q3 to dolny i górny kwartyl.
Rozstępy dla skali percentylowej (decylowej, centylowej)
Rozstępy miedzy percentylami to jedna z miar rozproszenia i określa procent wszystkich
obserwacji, których wartość znajduje się pomiędzy wybranymi percentylami.
Wariancja - mierzy stopień rozproszenia pomiarów wokół średniej arytmetycznej
- wariancja z próby.
gdzie xi to kolejne wartości zmiennej a to średnia arytmetyczna tych wartości, n - liczebność
próby,
- wariancja z populacji
gdzie xi to kolejne wartości zmiennej a µ to średnia arytmetyczna tych wartości, N - liczebność
populacji.
Odchylenie standardowe – mierzy stopień rozproszenia pomiarów wokół
średniej arytmetycznej.
- odchylenie standardowe z próby - odchylenie standardowe z populacji
Im wyższa wartość odchylenia standardowego, tym bardziej zróżnicowana grupa pod względem badanej cechy.
Uwaga! Odchylenie standardowe z próby jest przybliżeniem odchylenia standardowego z populacji. Populacyjna
wartość odchylenia standardowego mieści się w pewnym przedziale zawierającym odchylenie standardowe
z próby. Przedział ten nazywany jest przedziałem ufności dla odchylenia standardowego.
Współczynnik zmienności Współczynnik zmienności podobnie jak odchylenie standardowe pozwala na ocenę stopnia jednorodności
badanej zbiorowości. Wyraża się wzorem:
gdzie sd to odchylenie standardowe, to średnia arytmetyczna.
Jest to wielkość niemianowana. Pozwala on na ocenę zróżnicowania kilku zbiorowości
pod względem tej samej cechy oraz tej samej zbiorowości pod względem kilku różnych
cech (wyrażonych w różnych jednostkach). Przyjmuje się, że jeżeli współczynnik V nie przekracza 10%, to cechy wykazują zróżnicowanie statystycznie nieistotne.
Błąd standardowy średniej – nie jest miarą rozproszenia wyników
pomiarowych, lecz określa stopień dokładności, z jaką możemy określić wartość średniej arytmetycznej w
populacji na podstawie wyznaczenia średniej w analizowanej próbie.
Uwaga! Na podstawie bęłdu standardowego średniej można określić przedział ufności dla średniej.
Skośność inaczej współczynnik asymetrii
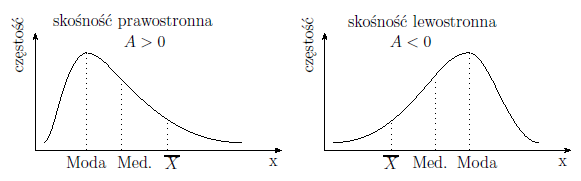
Jest to miara, która mówi o tym jak bardzo rozkład danych różni się od rozkładu symetrycznego. Im wartość współczynnika asymetrii jest bliższa zeru, tym bardziej symetrycznie wokół średniej rozkładają się dane. Zwykle wartość tego współczynnika zawiera się w przedziale [-1, 1], chociaż może w przypadku szczególnie dużej asymetrii znaleźć się poza tym przedziałem. Wartości dodatnie świadczą o występowaniu skośności prawostronnej (o dłuższym prawym ”ogonie”) wartości ujemne zaś o skośności lewostronnej (o dłuższym lewym ”ogonie”). Skośność wyraża się wzorem:
gdzie: xi – kolejne wartości zmiennej, , sd – odpowiednio średnia arytmetyczna i odchylenie standardowe xi,
n – liczność próby.
Kurtoza inaczej współczynnik koncentracji
Jest to miara, która mówi o tym jak bardzo rozrzut danych wokół średniej jest zbliżony do
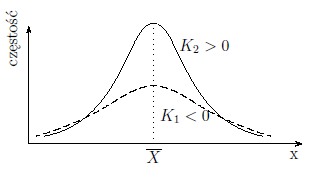
rozrzutu tych danych w rozkładzie normalnym. Im wartość kurtozy jest większa od zera,
tym badany rozkład jest bardziej smukły niż rozkład normalny a im wartość kurtozy jest
mniejsza od zera, tym badany rozkład jest bardziej spłaszczony niż rozkład normalny.
Kurtoza wyraża się wzorem:
gdzie: xi – kolejne wartości zmiennej, , sd – odpowiednio średnia arytmetyczna i odchylenie standardowe xi,
n – liczność próby.
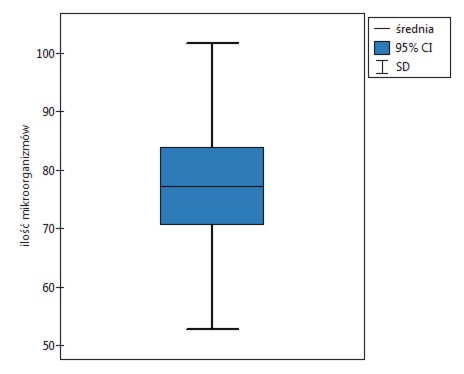
W doświadczeniu dotyczącym nawożenia gleby różnymi rodzajami preparatów mikrobiologicznych i nawozów wyliczono ilość mikroorganizmów występujących w 1 gramie suchej masy gleby. Chcemy wyznaczyć statystyki opisowe ilości promieniowcow dla próbki nawożonej azotem i zobrazować uzyskane wyniki za pomocą wykresu ramka-wąsy. Zaznaczamy w arkuszu danych tylko 54 pierwsze wiersze, które odpowiadają założeniom analizy (są to promieniowce nawożone azotem) i uruchamiamy okno Statystyki opisowe poprzez menu Statystyka › Statystyki opisowe.
W oknie opcji testu statystyk opisowych wybieramy zmienną do analizy: Ilość mikroorganizmów, a następnie procedury jakie chcemy wykonać (np. średnią arytmetyczną wraz
z przedziałem ufności, medianę, odchylenie standardowe wraz z przedziałem ufności oraz informacje o skośności i kurtozie rozkładu wraz z błędami). Na górze okna powinien być widoczny komunikat: Dane ograniczone przez zaznaczenie. By w raporcie znalazł się również wykres, zaznaczamy opcję Dołącz wykres i wybieramy interesujący nas rodzaj
wykresu ramka-wąsy. Potwierdzamy wybór przyciskiem OK i uzyskujemy wynik w postaci raportu:
 Statystyki opisowe
Statystyki opisowe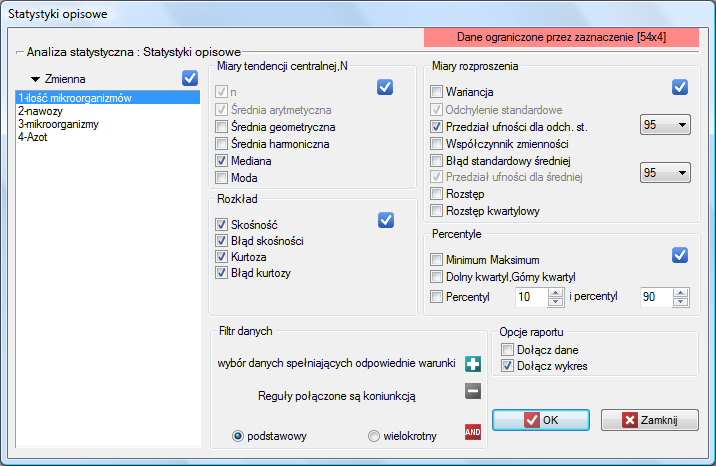
 . Dokonany wybór potwierdzamy przyciskiem OK.
Wynik dokonanej analizy znajdzie się w raporcie dołączonym do arkusza danych, dla
których analiza została wykonana.
. Dokonany wybór potwierdzamy przyciskiem OK.
Wynik dokonanej analizy znajdzie się w raporcie dołączonym do arkusza danych, dla
których analiza została wykonana.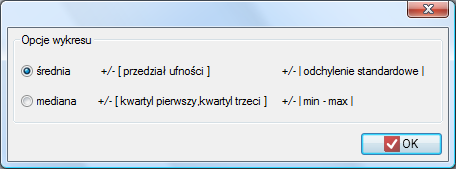
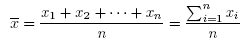
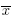 a dla populacji przez µ.
a dla populacji przez µ.