Regresja Cox'a, znana również jako model proporcjonalnego hazardu Cox'a (Cox PH model) - Cox D.R. (1972), jest najszerzej stosowanym podejściem regresyjnym w analizie przeżycia. Pozwala na zbadanie wpływu wielu zmiennych niezależnych (X1,X2, . . . ,Xk) na czas przeżycia. Jest to podejście w pewnym sensie nieparametryczne, a więc obarczone niewieloma założeniami - stąd też wynika jego popularność. Nie musi być znana natura ani kształt funkcji hazardu czy przeżycia, a najważniejszy warunek to założenie, które dotyczy również większości parametrycznych modeli przeżycia czyli proporcjonalność hazardu.
Funkcja, na której oparty jest model proporcjonalnego hazardu Cox'a opisuje hazard wynikowy i jest produktem dwóch wielkości, z których tylko jedna jest zależna od czasu (t):
gdzie:
h(t,X1,X2, . . . ,Xk) – wynikowy hazard opisujący zmieniające się w czasie ryzyko zależne od innych czynników np. sposobu leczenia, h0 - hazard bazowy, czyli hazard przy założeniu, że wszystkie zmienne objaśniające są równe zero, - kombinacja (najczęściej liniowa) zmiennych niezależnych i parametrów modelu, X1,X2, . . . ,Xk - zmienne objaśniające, niezależne od czasu, β1,β2, . . .βk - parametry.
Korekcja rang wiązanych w regresji Cox'a oparta jest na metodzie Breslow'a.
Rozwiązaniem równania regresji Cox'a jest wektor ocen parametrów β1,β2, . . .βk nazywanych współczynnikami regresji:
Współczynniki te szacowane są poprzez tzw. "częściową" metodę największej wiarygodności. Jest to metoda "częściowa" ponieważ poszukiwanie maksimum funkcji wiarygodności L (w programie użyto algorytm iteracyjny Newton-Raphson) odbywa się tylko dla danych kompletnych, dane ucięte są w tym algorytmie uwzględniane, ale nie bezpośrednio.
Uwaga!
Budując model należy pamiętać, że liczba obserwacji powinna być dziesięciokrotnie większa lub równa stosunkowi liczby szacowanych parametrów modelu (k) i mniejszej z proporcji liczności uciętych lub kompletnych (p), czyli (n >= 10k/p).
Uwaga!
Budując model należy pamiętać, że zmienne niezależne nie powinny być współliniowe. W przypadku gdy występuje współliniowość, estymacja może być niepewna a uzyskane wartości błędów bardzo wysokie.
Uwaga!
Kryterium zbieżności funkcji algorytmu iteracyjnego Newtona-Raphsona można kontrolować przy pomocy dwóch parametrów: limitu iteracji zbieżności (podaje maksymalną ilość iteracji w jakiej algorytm powinien osiągnąć zbieżność) i kryterium zbieżności (podaje wartość poniżej której uzyskana poprawa estymacji uznana będzie za nieznaczną i algorytm zakończy działanie).
Iloraz Hazardu
Dla każdej zmiennej niezależnej wyliczany jest jednostkowy Iloraz Hazardu (ang. Hazard Ratio - HR):
Wyraża on zmianę ryzyka niepożądanego zdarzenia, gdy zmienna niezależna rośnie o 1 jednostkę. Wynik ten jest skorygowany o pozostałe zmienne niezależne znajdujące się w modelu w ten sposób, że zakłada iż pozostają one na stałym poziomie podczas, gdy badana zmienna niezależna rośnie o jednostkę.
Wartość HR interpretujemy następująco:
HR > 1 oznacza stymulujący wpływ badanej zmiennej niezależnej na wystąpienie niepożądanego zdarzenia, tj. mówi o ile wzrasta ryzyko na wystąpienie niepożądanego zdarzenia, gdy zmienna niezależna wzrasta o jeden poziom.
HR < 1 oznacza destymulujący wpływ badanej zmiennej niezależnej na wystąpienie niepożądanego zdarzenia, tj. mówi o ile spada ryzyko na wystąpienie niepożądanego zdarzenia, gdy zmienna niezależna wzrasta o jeden poziom.
HR ≈ 1 oznacza, że badana zmienna niezależna nie ma wpływu na wystąpienie niepożądanego zdarzenia.
Uwaga!
Jeśli analizę przeprowadzamy dla modelu innego niż liniowy, lub uwzględniamy interakcję, wówczas analogicznie jak w modelu regresji logistycznej na podstawie ogólnego wzoru możemy wyliczyć odpowiedni HR zmieniając formułę będącą kombinacją zmiennych niezależnych.
Weryfikacja modelu
Istotność statystyczna poszczególnych zmiennych w modelu (istotność ilorazu szans)
Na podstawie współczynnika oraz jego błędu szacunku możemy wnioskować czy zmienna niezależna, dla której ten współczynnik został oszacowany wywiera istotny wpływ na zmienną zależną. W tym celu posługujemy się testem Walda.
Hipotezy:
lub równoważnie
Wyznaczoną na podstawie statystyki testowej wartość p porównujemy z poziomem
istotności α
jeżeli p ≤α ⇒ odrzucamy H0 przyjmując H1,
jeżeli p >α ⇒ nie ma podstaw odrzucić H0.
Jakość zbudowanego modelu regresji logistycznej
Dobry model powinien spełniać dwa podstawowe warunki: powinien być dobrze dopasowany i możliwie jak najprostszy. Jakość modelu proporcjonalnego hazardu Coxa możemy ocenić kilkoma ogólnymi miarami, które opierają się na: LFM – maksimum funkcji wiarygodności modelu pełnego (z wszystkimi zmiennymi), L0 – maksimum funkcji wiarygodności modelu zawierającego jedynie wyraz wolny, d –obserwowanej liczbie niepożądanych zdarzeń.
Kryteria informacyjne opierają się na entropii informacji niesionej przez model (niepewności modelu) tzn. szacują utraconą informację, gdy dany model jest używany do opisu badanego zjawiska. Powinniśmy zatem wybierać model o minimalnej wartości danego kryterium informacyjnego AIC, AICc i BIC jest rodzajem kompromisu pomiędzy dobrocią dopasowania i złożonością. Drugi element sumy we wzorach na kryteria informacyjne (tzw. funkcja straty lub kary) mierzy prostotę modelu. Zależy on od liczby prarametrów w modelu (k) i liczby obserwacji kompletnych (d). W obu przypadkach element ten rośnie wraz ze wzrostem liczby parametrów i wzrost ten jest tym szybszy im mniejsza jest liczba obserwacji. Kryterium informacyjne nie jest jednak miarą absolutną, tzn. jeśli wszystkie porównywane modele źle opisują rzeczywistość w kryterium informacyjnym nie ma sensu szukać ostrzeżenia.
Kryterium informacyjne Akaikego (ang. Akaike information criterion) - jest to kryterium asymptotyczne - odpowiednie dla dużych prób.
Poprawione kryterium informacyjne Akaikego - poprawka kryterium Akaikego dotyczy wielkości próby (liczby zdarzeń niepożądanych), przez co jest to miara rekomendowana również dla prób o małych licznościach.
Bayesowskie kryterium informacyjne Schwartza (ang. Bayes Information Criterion lub Schwarz criterion) - podobnie jak poprawione kryterium Akaikego uwzględnia wielkość próby (liczbę zdarzeń niepożądanych) - Volinsky i Raftery 2000.
Pseudo R2 tzw. McFadden R2 jest miarą dopasowania modelu (odpowiednikiem współczynnika determinacji wielorakiej R2 wyznaczanego dla liniowej regresji wielorakiej). Wartość tego współczynnika mieści się w przedziale< 0; 1), gdzie wartości bliskie 1 oznaczają doskonałe dopasowanie modelu, 0 –zupełny bark dopasowania. Wadą współczynnika Pseudo R2 jest wrażliwość na ilość zmiennych w modelu i brak możliwości osiągnięcia g??rnej granicy 1. Dlatego też wyznacza się jego poprawioną wartość: R2Nagelkerke i R2Cox-Snell
Istotność statystyczna wszystkich zmiennych w modelu Podstawowym narzędziem szacującym istotność wszystkich zmiennych w modelu jest test ilorazu wiarygodności. Test ten weryfikuje hipotezę:
:
wszystkie βi = βi,
:
nie wszystkie βi ≠ βi.
Wyznaczoną na podstawie statystyki testowej wartość p porównujemy z poziomem istotności α
jeżeli p ≤α ⇒ odrzucamy H0 przyjmując H1,
jeżeli p >α ⇒ nie ma podstaw odrzucić H0.
Analiza reszt modelu
Analiza reszt modelu pozwala na weryfikację jego założeń. Głównym jej celem w regresji Cox'a jest lokalizacja wartości odstających i badanie proporcjonalności hazardu. Standardowo w modelach regresji reszty oblicza się jako różnice obserwowanych i przewidywanych przez model wartości zmiennej zależnej. Jednakże w przypadku występowania zmiennych uciętych taka koncepcja wyznaczania reszt nie jest odpowiednia. W programie można analizować reszty opisywane jako: Martingale, Deviance, Schoenfeld. Reszty te można wyrysowywać względem czasu lub zmiennych niezależnych.
Założenie proporcjonalności hazardu
Opracowano szereg graficznych metod pozwalających na ocenę adekwatności modelu proporcjonalnego hazardu (Lee i Wang 2003). Najszerzej stosowane są metody bazujące na resztach modelu. Podobnie jak inne graficzne metody oceny proporcjonalności hazardu jest to metoda subiektywna. Aby założenie proporcjonalnego hazardu było spełnione reszty względem czasu nie powinny układać się w żaden wzór ale powinny być losowo rozłożone w okolicach wartości 0.
Martingale - reszty te mogą być interpretowane jako różnica w czasie [0, t] pomiędzy obserwowaną licznością zdarzeń niepożądanych i przewidywaną przez model licznością tych zdarzeń. Wartość oczekiwana dla tych reszt to 0, ale ich wadą jest skośny rozkład utrudniający interpretację ich wykresu (zawierają się w przedziale od -∞ do 1).
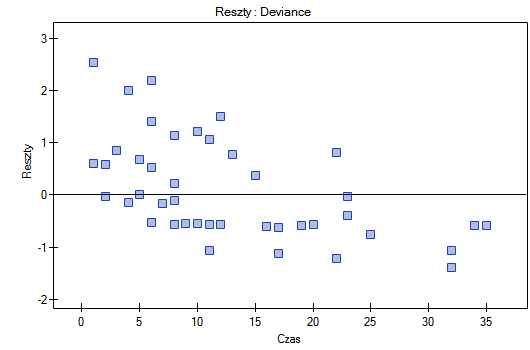
Deviance - podobnie jak Martingale aasymptotycznie uzyskują wartość oczekiwaną równą 0, ale rozkładają się symetrycznie wokół zera z odchyleniem standardowym równym 1, gdy dopasowywany model jest odpowiedni. Wartość Deviance jest dodatnia, gdy obiekt badany przeżywa krócej niż oczekiwany na podstawie modelu czas, a ujemna gdy ten czas jest dłuższy. Analiza tych reszt jest wykorzystywana w badaniu proporcjonalności hazardu - ale jest to przede wszystkim narzędzie identyfikujące wartości odstające. W raporcie reszt, te z nich, które są oddalone o więcej niż 3 odchylenia standardowe od 0 oznaczone są kolorem czerwonym.
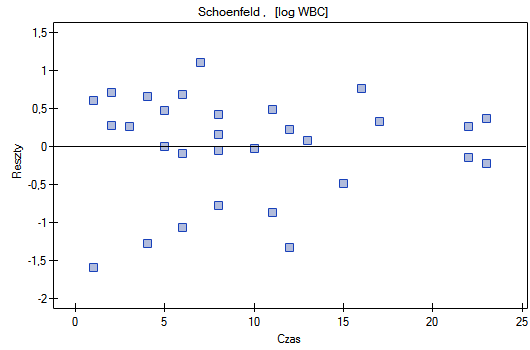
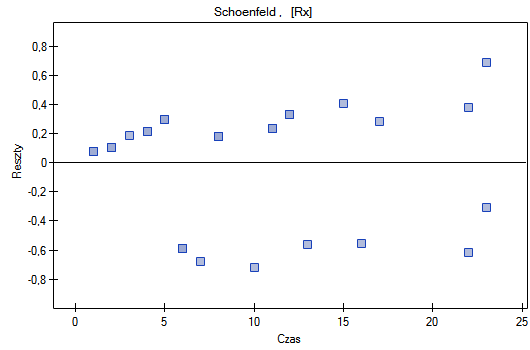
Schoenfeld - reszty te wyliczane są oddzielnie dla każdej zmiennej niezależnej i definiowane tylko dla obserwacji kompletnych. Dla każdej zmiennej niezależnej suma reszt Schoenfeld'a i ich wartość
oczekiwana to 0. Zaletą przedstawiania reszt względem czasu dla każdej zmiennej jest możliwość zidentyfikowania zmiennej nie spełniającej w modelu założenia proporcjonalności hazardu. Jest to ta zmienna, której wykres reszt układa się w systematyczny wzór (najczęściej bada się tu liniową zależność reszt od czasu). Równomierne rozłożenie punktów względem wartości 0 świadczy o braku zależności reszt od czasu - czyli spełnieniu założenia proporcjonalności hazardu przez daną zmienną w modelu.
Gdy dla którejkolwiek zmiennej w modelu Cox'a nie jest spełnione założenie proporcjonalności hazardu, jednym z możliwych rozwiązań jest wykonanie analizy Cox'a oddzielnie dla każdego poziomu tej zmiennej.
Analiza opiera się na danych dotyczących białaczki opisanych w pracy Freireich i innych 1963 i analizowanych dalej przez wielu autorów min. Kleinbaum i Klein 2005. Dane zawierają informację o czasie (w tygodniach) pozostawania w remisji aż do momentu wycofania pacjenta z badania z powodu wyjścia z remisji (nawrotu objawów) lub ucięcia informacji o pacjencie. Wyjście z remisji jest nastąpieniem zdarzenia niekorzystnego - traktowane jest jako obserwacja kompletna. Obserwacja jest ucięta jeśli pacjent pozostaje w badaniu do końca i remisja nie nastąpi lub jeśli opuści badanie. Pacjenci przydzieleni zostali do dwóch grup: grupy leczonej tradycyjnie (oznaczonej jako 1 i czasami zazywanej "grupą placebo") i grupy leczonej nową metodą (oznaczonej jako 0). Zebrano informację o płci pacjentów (1=mężczyzna, 0=kobieta) oraz o wartościach wskaźnika określającego liczbę białych krwinek oznaczonego jako "log WBC", który jest znanym czynnikiem prognostycznym.
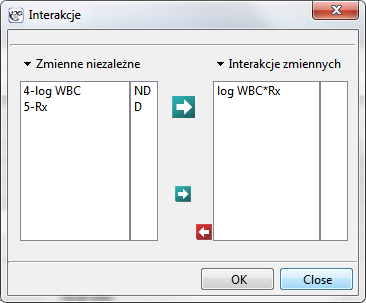
Celem badania jest określenie wpływu sposobu leczenia na czas pozostawania w remisji przy uwzględnieniu możliwych czynników wikłających (confounder) i interakcji. W analizie uwagę skupimy na zmiennej "Rx (1=placebo, 0=new treatment) ", zmienną "log WBC" umieścimy w modelu jako możliwy czynnik wikłający (modyfikujący uzyskany efekt). By ocenić ewentualny wpływ interakcji "Rx" i "log WBC" rozważymy także trzecią zmienną będącą iloczynem zmiennych wchodzących w skład interakcji. Zmienną tę dołączymy do modelu wybierając w oknie analizy przycisk Interakcje i dokonując odpowiednich ustawień.
Budujemy trzy modele Coxa:
Model A zawiera tylko zmienną "Rx"
Model B zawiera zmienną "Rx" i potencjalną zmienną wikłającą "log WBC"
Model C zawiera zmienną "Rx" zmienną "log WBC" oraz potencjalny efekt interakcji tych zmiennych: "Rx × log WBC"
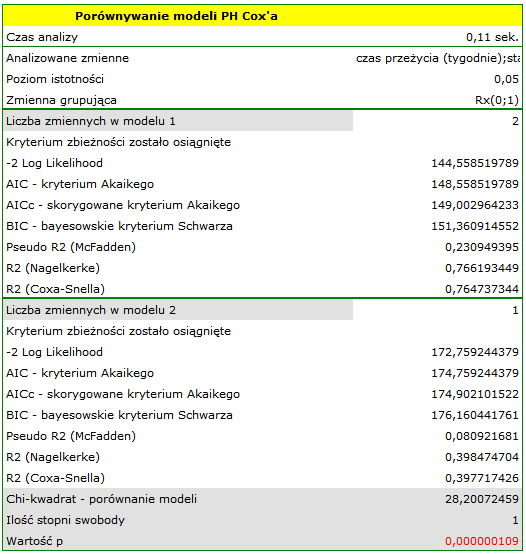
Zmienna mówiąca o interakcji "Rx" i "log WBC", zawarta w modelu C jest w nim nieistotna (p=0.5103) według testu Walda. Możemy więc uznać za zbyteczne dalsze rozważanie w modelu interakcji tych dwóch zmiennych. Podobne wyniki uzyskamy porównując testem Ilorazu Wiarygodności model C z modelem B. Porównanie to możemy wykonać wybierając menu Regresja Cox’a - porównywanie modeli, uzyskamy wówczas wynik nieistotny (p=0.5134), co oznacza, że model C (model z interakcją) jest NIEistotnie lepszy niż model B (model bez interakcji).
Odrzucamy więc model C przechodząc do rozważania modelu B i modelu A.
HR dla "Rx" w modelu B wynosi 3.65, co oznacza, że hazard dla "grupy placebo" jest około 3.6 większy niż dla grupy pacjentów leczonych nową metodą. Model A zawiera tylko zmienną "Rx", przez co nazywany jest zwykle modelem "surowym" (ang. crude model) ponieważ ignoruje efekt potencjalnych zmiennych wikłających. W modelu tym HR dla "Rx" wynosi 4.52 i jest sporo większe niż w modelu B. Przyjrzyjmy się jednak nie tylko punktowym wartościom estymatora HR ale również 95% przedziałowi ufności dla tych estymatorów. Przedział dla "Rx" w modelu A ma szerokość 8.06 (10.09 minus 2.03) a w modelu B jest węższy: 6.74 (8.34 minus 1.60). Dlatego model B daje bardziej precyzyjną estymację HR niż model A. By ostatecznie zdecydować, który model (model A czy model B) będzie lepszy w oszacowaniu efektu leczenia ("Rx") ponownie wykonujemy analizę porównawczą modeli w module Regresja Cox’a - porównywanie modeli. Tym razem test Ilorazu Wiarygodności daje wynik istotny (p<0.0001), co ostatecznie potwierdza wyższość modelu B. Jest to model o najniższej wartości kryteriów informacyjnych (AIC=148.6, AICc=149 BIC=151.4) i wysokich wartościach dopasowania modelu (Pseudo R2McFadden = 0.2309, R2Nagelkerke = 0.7662, R2Coxa-Snella = 0.7647).
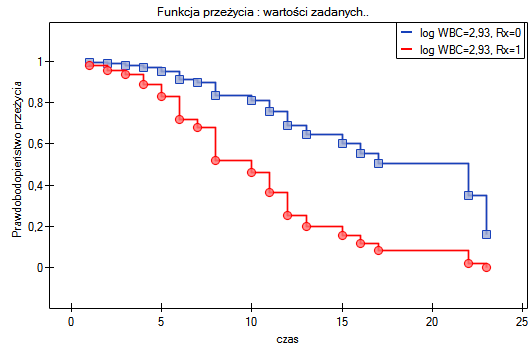
Dopełnieniem powyższej analizy jest przedstawienie dla modelu B krzywych przeżycia (pozostawania w remisji) obu grup: leczonej nowym lekiem i tradycyjnie, skorygowanych o wpływ "log WBC". Na wykresie obserwujemy różnice między grupami, występujące w poszczególnych punktach osi czasu. By wyrysować takie krzywe, po wybraniu opcji Dołącz wykres zaznaczam opcję Funkcja przeżycia: wartości zadanych ... oraz ustawiam wartości dla zmiennej "Rx" na 0 dla pierwszej krzywej (osób leczonych nowym lekiem) i 1 dla drugiej krzywej (osób leczonych tradycyjnie), dla zmiennej "Log WBC" wpisuję wartość średnią czyli 2.93.
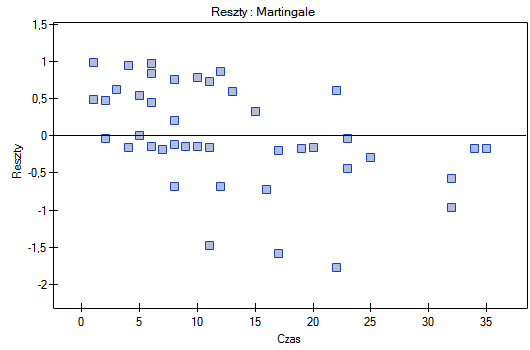
Na koniec ocenimy założenia regresjii Cox'a analizując reszty modelu względem czasu.
Nie obserwujemy odstających punktów, aczkolwiek reszty Martingale i Deviance są coraz niższe dla coraz dłuższego czasu. Natomiast reszty Schoenfeld'a przedstawiają symetryczny rozkład względem czasu. W przypadku reszt Schoenfeld'a analizę wykresu można wesprzeć różnego rodzaju testami mogącymi ocenić, czy punkty wykresu reszt układają się w pewien wzór np. zależność liniową. By tej analizy dokonać należy przekopiować reszty Schoenfeld'a oraz czas do arkusza danych i przetestować szukany rodzaj zależności. Wynik takiego testu dla każdej zmiennej wskazuje na spełnienie założenia proporcjonalności hazardu przez daną zmienną w modelu - gdy jest nieistotny statystycznie lub złamanie tego założenia - gdy jest istotny statystycznie. W rezultacie zmienną łamiącą założenia regresji proporcjonalnego hazardu Cox'a można wyłączyć z modelu. W przypadku zmiennych "Log WBC" i "Rx" symetryczny rozkład reszt sugeruje spełnienie założenia proporcjonalności hazardu przez te zmienne. Potwierdzeniem tego może być sprawdzenie zależności np. liniowej Pearsona, lub monotonicznej Spearmana dla tych reszt i czasu.
Dalej możemy dodać do modelu zmienną płeć. Musimy jednak postępować ostrożnie, gdyż na podstawie różnych źródeł wiadomo, że płeć może wpływać na funkcję przeżycia (pozostawania w remisji) dotyczącą białaczki w ten sposób, że funkcje przeżycia mogą układać się nieproporcjonalnie względem siebie wzdłuż osi czasu. Wykonujemy więc model Cox'a dla trzech zmiennych: zmiennej "Płeć", "Rx" i "log WBC". Zanim dokonamy interpretacji współczynników modelu sprawdzimy reszty Shoenfeld'a. Reszty przedstawiamy na wykresach, a wyniki reszt Shoenfeld'a oraz czasu przekopiujemy z raportu do nowego arkusza, gdzie sprawdzimy występowanie zależności monotonicznej Spearmana. W wyniku uzyskujemy wartość p=0.0259 (dla zależności czasu i reszt Shoenfeld'a dla płci), p=0.6192 (dla zależności czasu i reszt Shoenfeld'a dla log WBC) i p=0,1490 (dla zależności czasu i reszt Shoenfeld'a dla Rx) co potwierdza naruszenie założenia proporcjonalności hazardu przez zmienną płeć. Model Cox'a zbudujemy więc oddzielnie dla kobiet i mężczyzn. W tym celu analizę wykonamy dwukrotnie z włączonym filtrem danych. Za pierwszym razem filtr będzie wskazywał płeć żeńską (0), a za drugim razem płeć męską (1).
 Analiza przeżycia
Analiza przeżycia
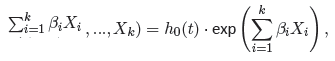
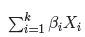 - kombinacja (najczęściej liniowa) zmiennych niezależnych i parametrów modelu,
- kombinacja (najczęściej liniowa) zmiennych niezależnych i parametrów modelu,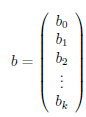
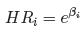
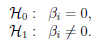
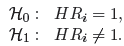
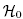 :
wszystkie βi = βi,
:
wszystkie βi = βi,
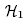 :
nie wszystkie βi ≠ βi.
:
nie wszystkie βi ≠ βi.